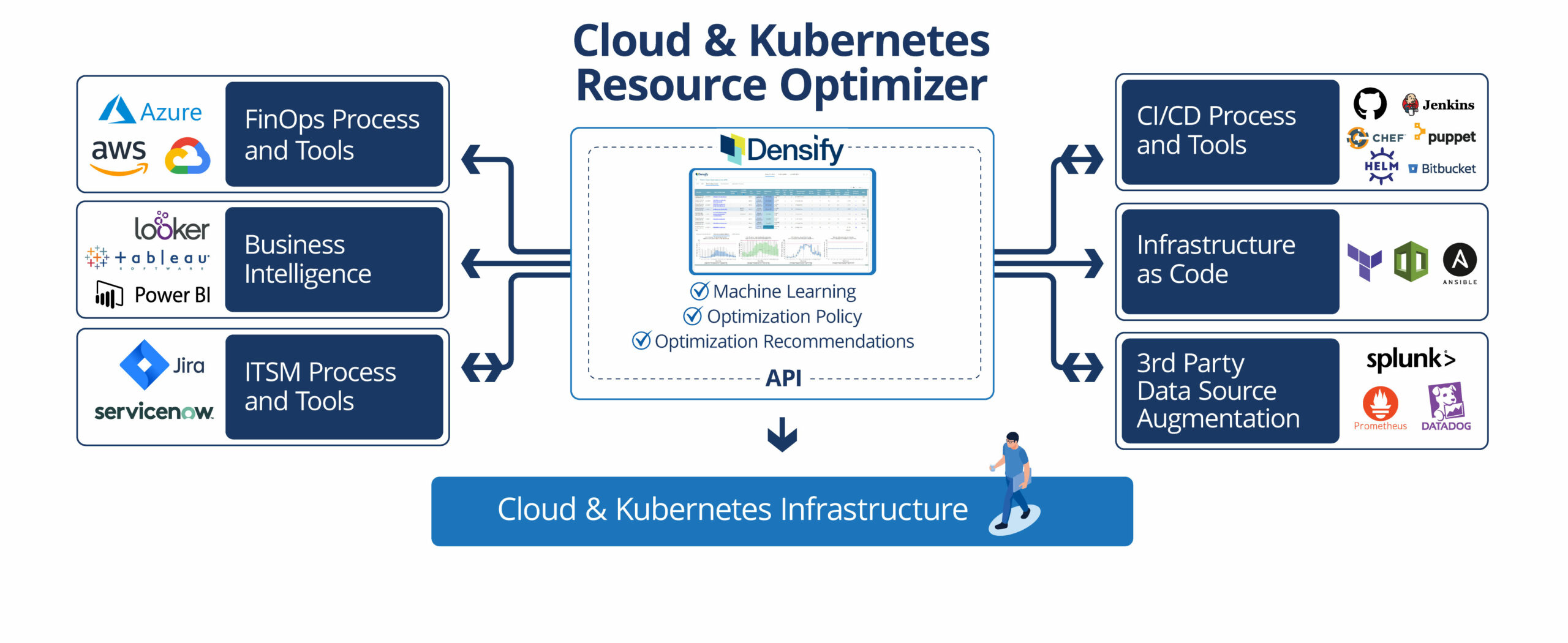
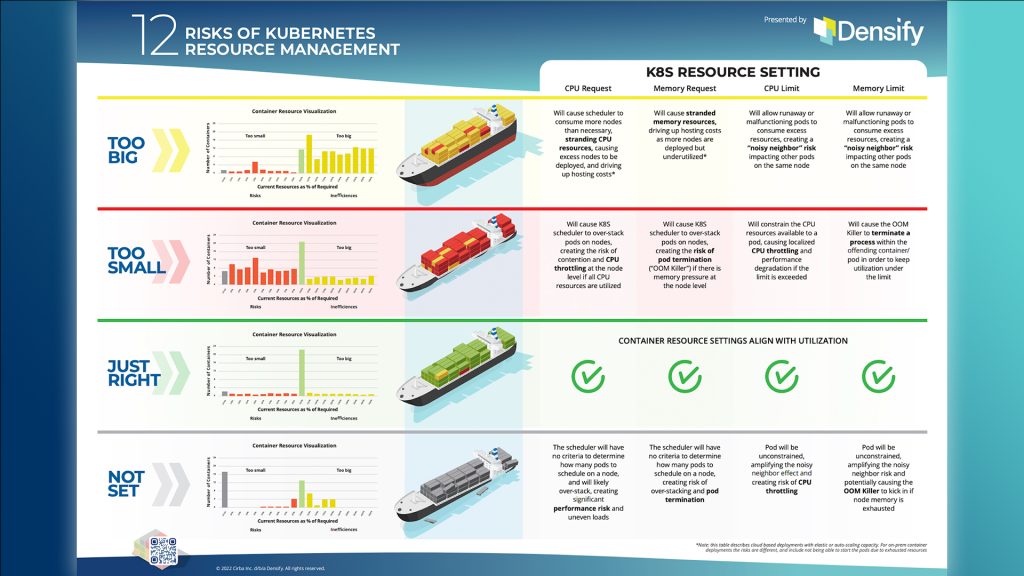
Densify equips Engineers, SRE’s and technical teams to improve the performance and reduce the cost of Cloud and Kubernetes Infrastructure
We empower engineers to make better decisions and waste less
We integrate an engine that works every day to align resources with demand
We don't help you understand your cloud bill – it's not our focus
Ask us how these enterprises are succeeding with Densify
Found 200 pods at risk of pod or process termination
Identified over 5,000 containers with no request and limits set
Remediated nodes running at full memory utilization by setting correct requests
AI company saves $5.4M in less than a year
One of America's largest Insurers used gamification to drive $75k in cost avoidance in just 12 weeks
Energy company reduced cloud spend by 34% in 2 months
Telecom company achieves $1.5M in savings over 3 years
Top 10 SaaS company saves $4M in less than a year
Energy company reduced cloud spend by 34% in 2 months
Incredible New Cloud Catalog Map!
See your cloud provider’s offerings in ways never before possible.
In one view, see a given workload and how well suited it is by its current instance capabilities and size. In the same view, see what Densify advanced analytics says is the best selection for that workload, visualizing the entire cloud catalog.
Adjust a flexible spend tolerance to reduce the number of choices based on technical and feature fit, but also how wasteful or efficient the other choices would be.
Enable Engineers and App owners to make better decisions and drive down cost at the same time.
Intel® Cloud Optimizer, powered by Densify is a joint offering that combines workload specific expertise from Intel with leading analytics to get your apps onto the best possible infrastructure possible.
Intel® Cloud Optimizer, powered by Densify is a joint offering that combines workload specific expertise from Intel with leading analytics to get your apps onto the best possible infrastructure possible.
We’re glad you are here! Densify customizes your experience by enabling cookies that help us understand your interests and recommend related information. By using our sites, you consent to our use of cookies. Learn more.